Project Description
This project focuses on performing a complete Extract, Transform, Load (ETL) pipeline on a real-world crowdfunding dataset sourced from Excel spreadsheets. The project aims to clean, normalize, and restructure raw data into a well-organized PostgreSQL relational database. The end goal is to make the data easy to analyze and derive insights from.
Extraction of Data
The raw data was extracted from the following Excel files:
- crowdfunding.xlsx – Contains campaign details including category, subcategory, funding goals, dates, and more.
- contacts.xlsx – Contains embedded JSON-formatted contact information.
Process:
- The main campaign data was read using Pandas Python library.
- The category and subcategory columns were split from the combined category & sub-category field.
- Unique categories and subcategories were extracted into lists.
- The contact spreadsheet was parsed from a JSON-like structure embedded in a single column, with each row converted into structured rows of contact info.
Data Transformation
The transformation phase included restructuring the data into normalized formats across several DataFrames:
Category and Subcategory
- Unique categories and subcategories were each assigned a unique ID using list comprehensions.
- Prefixes were added to generate readable IDs.
- Resulting data was stored in category.csv and subcategory.csv
Campaign
- Data formatting such as renaming columns and type conversions.
- Merged campaign data with category and subcategory dataframes to add respective IDs.
- Exported as campaign.csv
Contacts Transformation
- Parsed JSON strings from the contacts Excel file.
- Extracted and split name into first_name and last_name.
- Reorganized columns and validated datatypes.
- Exported as contacts.csv
Load
The cleaned and transformed CSV files (category.csv, subcategory.csv, campaign.csv, contacts.csv) were loaded into a PostgreSQL database using 'SQL CREATE TABLE' and 'COPY' commands. Primary keys and foreign keys were defined based on the ERD created by Amanda, ensuring relational integrity.
Data Analysis
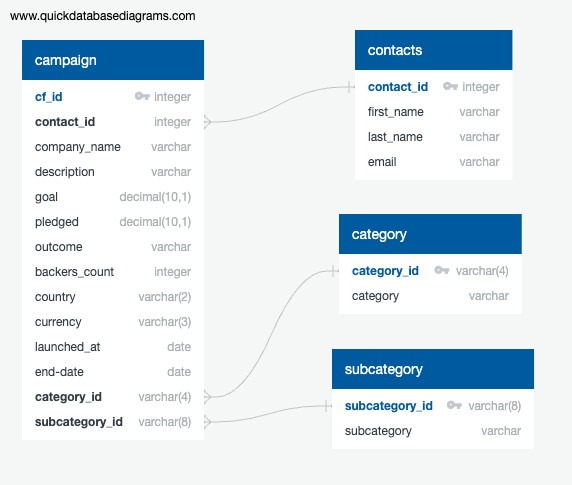
With a structured schema in PostgreSQL:
- Queries can now efficiently join campaign with contacts, category, and subcategory to analyze: which categories raise the most funding, which campaigns perform best over time, and user-specific campaign trends.
- Dates are now in SQL-friendly format, enabling time-series analysis.
- Normalization improves performance and simplifies visualizations for future dashboards (such as Tableau, Power BI).
Conclusion
This project successfully demonstrated the use of ETL processes to clean, structure, and analyze real-world data. Each team member's contribution was vital to creating a normalized database ready for insightful queries and analysis.